[toc]
Chapter 5: Large and Fast: Exploiting Memory Hierarchy
本章目标:
Introduction#
存储容量的数量级:
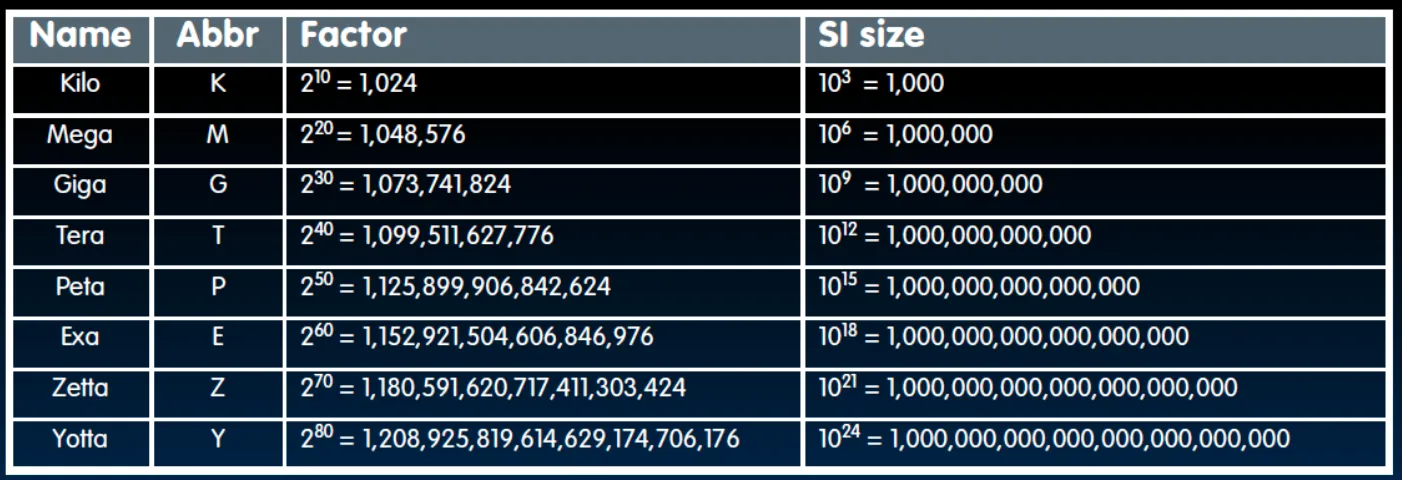
**存储系统的层次:**从 CPU 开始,由近到远,速度由快到慢,容量由小到大,价格越来越低:

Principle of Locality:
-
时间局部性
-
最近访问数据或指令可能会被再次访问。
-
例如循环中的变量、频繁调用的函数。
-
-
空间局部性
-
与最近访问位置相邻的数据也可能被访问。
-
例如数组的顺序遍历、顺序指令执行。
-
上述存储结构可以根据这两者,让存储系统更快。
Memory Technology#
常用存储技术:
- Static RAM, SRAM
- 用于 Cache,最快。
- 由六晶体管构成,数据一直保存在稳定电路状态中,断电即丢失。
- Dynamic RAM, DRAM
- 用于 Memory,比 Cache 慢但便宜。
- 每个 bit 由电容 + 晶体管组成,用电荷表示0/1
- 需要周期性 Refresh 电荷,避免状态消失,断电即丢失。
- Flash Memory
- 是固态硬盘
- 通过电荷存储在浮栅晶体管来记忆,长期保留。
- Magnetic disk
- 是机械硬盘
- 由旋转磁盘表面+读写磁头组成,通过磁化方向存储信息,长期保留信息。
Cache Basics#
Cache 是 Memory 部分内容的映像,通过 Cache 可以快速访问 Memory 中的数据,从而提高系统性能。
Memory 和 Cache 之间以**块(Block)**为单位进行数据传输。
下面假设在 32 位机器上,一个块的大小是 4 bytes,一个 byte 有 8 位,地址共 32 位长。但实际考试中,可能会考察其他自定义情况。
Memory 地址结构#
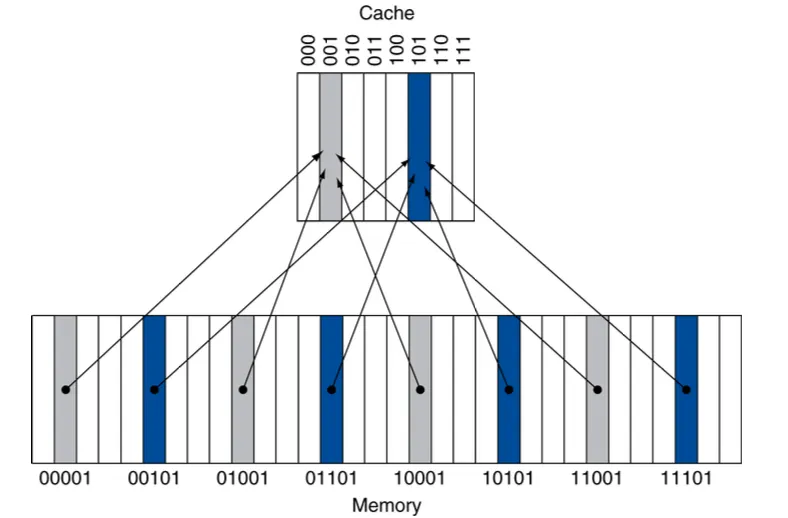
**Memory 地址结构:**从高位到低位划分为 | Tag | Index | Offset |
- Tag:标识该块来自 Memory 的哪个地址范围。
- Index:标识该块在 Cache 中的位置,Tag + Index 是精确到块的地址。
- Offset:精确到字节的地址,标识该块内的具体字节位置。
Direct Mapped Cache 映射方式#
Direct Mapped Cache:把 Memory 块号(Tag + Index),通过取模运算得到 Index,根据 Index 决定其映射到 Cache 中的哪个块。
Cache 块结构#
Cache 块结构: | Valid | Tag | Data |
- Valid:标识该块是否包含有效数据。valid = 0 代表该块为空,valid = 1 代表该块有有效数据。清零 Cache 时只需要写 0 即可。
- Tag:存储 Memory 地址的 Tag 部分,这样标记该块在 Memory 中的位置。
- Data:存储从 Memory 读取的数据块。
Cache 访问流程#
当 CPU 访问 Memory 地址时:
- 使用 Memory 的 Index 字段送到译码器,译码器定位到 Cache 的对应块。
- 比较 Memory 地址的 Tag 与 Cache 块中存储的 Tag。
- 如果 Tag 匹配且 Valid = 1,则命中(Hit),使用 Offset 从 Data 中提取数据。根据 Offset 决定返回哪个字节。
- 如果 Tag 不匹配或 Valid = 0,则未命中(Miss),需要从 Memory 加载数据到 Cache。
Block Size#
Block Size 越大,
- 命中率越高,更多数据更快访问。
- 同一个块会被不同任务频繁调度,更频繁的改内容,引起污染问题。
- 需要更长的传输时间,因为要传输更多的数据。
- 这个问题可以用 critical word first 策略解决,先传输关键字,再传输其他数据。
因此需要根据 CPU 属性,选择合适的 Block Size。
Cache Write Policies 写策略#
Write-Through#
若 Cache Hit,则同时写入 Memory 和 Cache。
但是这个方法很慢。
一般需要 Write buffer 优化一下,CPU 写到 buffer 之后就可以继续干别的了,buffer 慢慢写到 memory 里面。
Write-Back#
若 Cache Hit,只写入 Cache,不写入 Memory。
增加硬件支持:
- 给 Cache 增加一位
Dirty位,若 Dirty = 1,则表示 Cache 块内容被修改,与 Memory 不同步。 - 当 Cache 块即将被新内容替换时,若 Dirty = 1,则写入 Memory。
- MSI 协议?
Write Allocation#
若 Cache Miss,
- 对于 Write-Through 策略,都可以。
- 对于 Write-Back 策略:先把内容读到 Cache 中,然后写 Cache 的内容并标记 Dirty.
Cache Performance#
Cache 命中率越高,Pipeline 阻塞越少,性能越好。下面讨论如何评价 Cache 命中率。
需要先计算 Memory Stall Cycles,然后计算 CPI。
其中:
- Memory Stall Cycles 是 Cache Miss 的惩罚总周期数。
- Instruction Count 是程序中指令的总数
- Miss Rate 是每条指令平均 Cache Miss 的概率,计算方法是 Misses / Instruction
- Miss Penalty 是 Cache Miss 的惩罚周期数。
CPI 计算#
这部分常用,并结合后面的内容一起考。
由于通常用 CPI 来评价 CPU 性能,这里也用 CPI 来评价 Cache 性能。
其中:
- Base CPI 的含义是:假设所有访存都不发生 stall(即理想 Cache / 理想内存)的情况。
Average memory access time, AMAT#
Average memory access time (AMAT) 是 Cache 的平均访问时间。通常以 CPU 周期为计量单位。
因为任何一次访问,最开始都要从 Cache 读一下试试,所以 Hit Time 概率为 。
其中:
- Hit Time 是 Cache Hit 的访问时间。
- Miss Rate 是 Cache Miss 的概率。
- Miss Penalty 是 Cache Miss 的惩罚时间。
Performance Summary#
综上所述,要提高性能,只能通过提高 Cache 命中率,具体方法包括:
- 增加块大小 Block Size;
- 增加相联度 Associativity、替换算法;
- 增加多级 Cache。
具体方法会在下文中介绍。
Associative Caches 相联缓存与替换#
Associative Caches 相联缓存#
- Fully associative 全相联:
- 允许 Memory 中的任意块,都可以映射到 Cache 中的任意一个块。
- 但需要存储全部的 Tag + Index,成本高。
- 每个条目都需要设计一个比较电路,成本高,功耗高。
- n-way associative 组相联:
- 对 Cache Block 分组,n-way 代表一组里有 n 个块。
- 核心策略:组内使用全相联,组间使用直接映射。
- Memory 先对组数取模得到 Index,然后根据 Index 找到对应的组;组内任意存放,使用全相联的方式查找。
- 一个组有多少块,就需要多少个比较电路。
- 相对于全相联,减少了比较电路的数量。
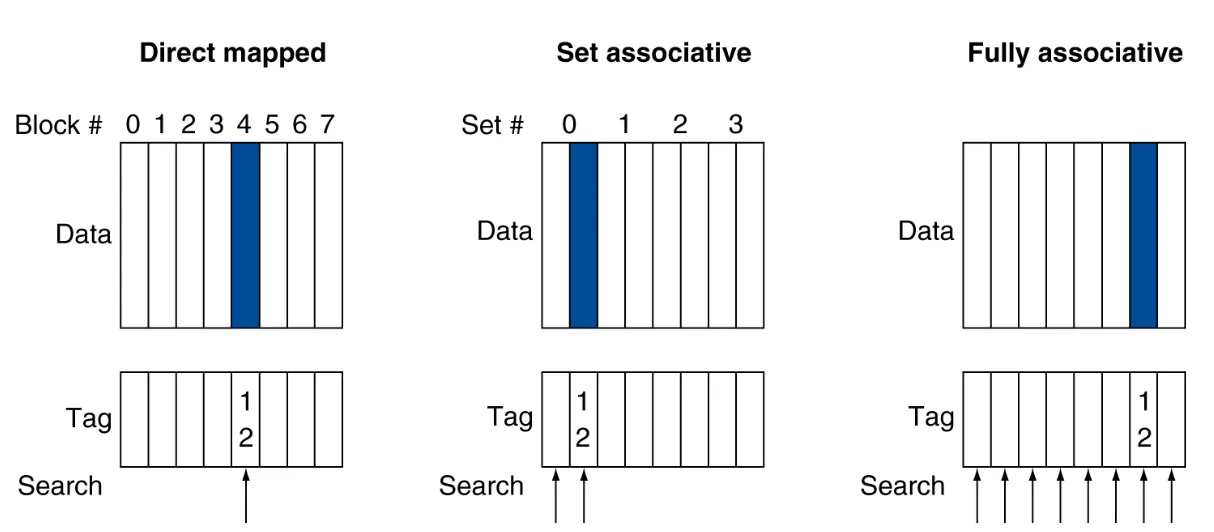
相联度:组相联的相联度为 n,全相联的相联度为 Cache Block count,直接映射的相联度为 1。
相联度越高,命中率越高。但相联度过高后,组合电路过于复杂,提升效果有限,会导致成本功耗提高。
因此需要根据实际情况选择合适的相联度。
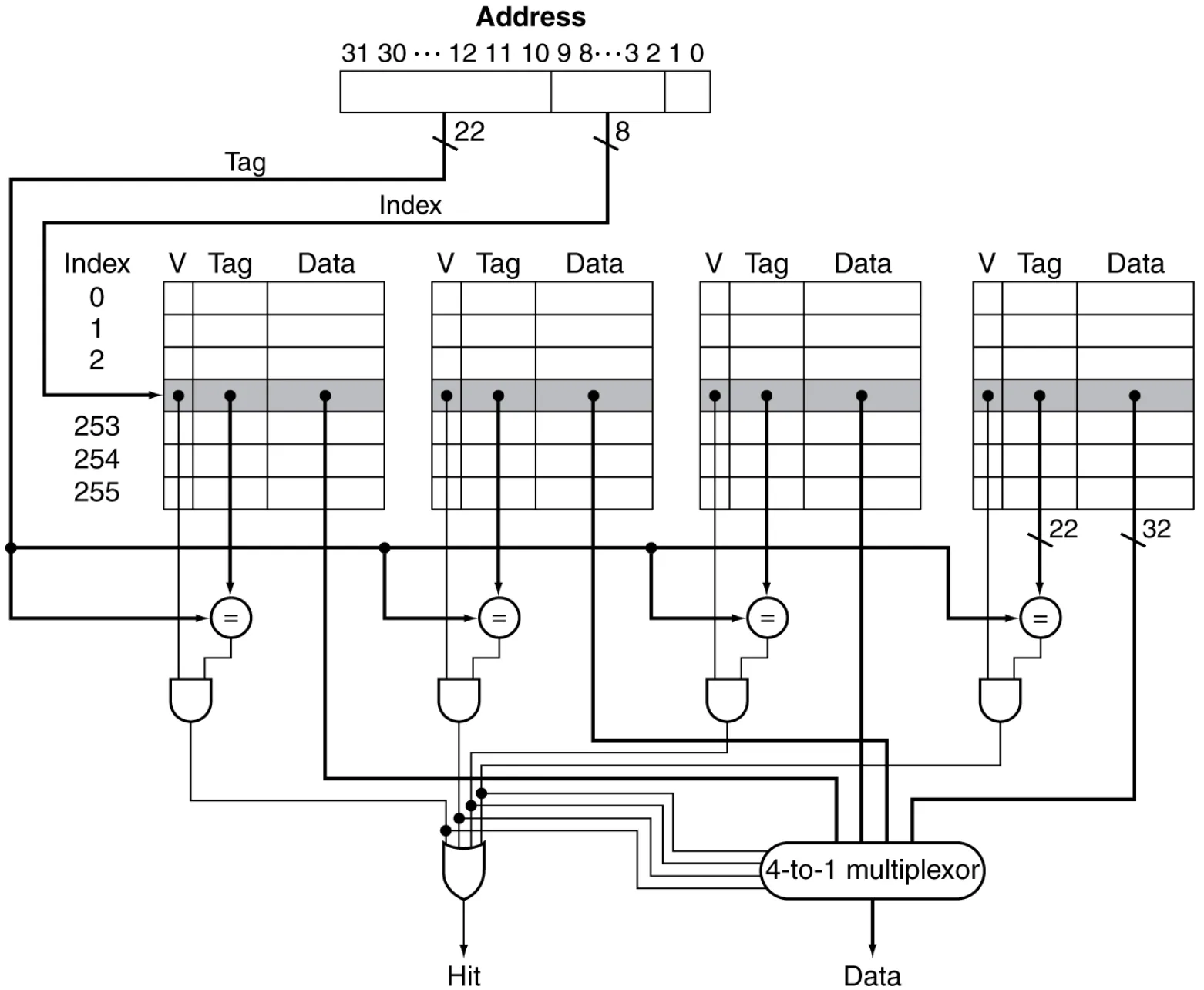
如上图所示,是一个 4-相联度的 Cache。
先通过 Address 的 Index 定位到某一组,即一行的 4 个块,之后再在组内根据 Tag 查找。
Replacement Policies 替换策略#
在组相连 Cache 中,优先写入 non-valid 的块。
然而,当一个组满了,需要再存一个块时,需要选择一个块进行替换。有如下策略。
- Least-recently used, LRU:
- 选择最近最少使用的块进行替换。
- 对于 2-way 或者 4-way 还可以用电路实现,太大的时候就很难实现。
- 严格实现需要时间戳,时间成本很高。
- 因此实际情况下,会用一些其他方法近似实现。
- Random:
- 随机选择一个块进行替换,一些情况下表现并不差。
Multilevel Caches#
结构#
- Primary Cache:集成在 CPU 中,速度最快,容量最小。
- Level-2 Cache:集成在主板,也有在 CPU 中的,更慢,更大。
访问#
先访问 L1,若未命中,则访问 L2,若未命中,则访问 Memory。访问到了之后,将数据写回 L1 和 L2。
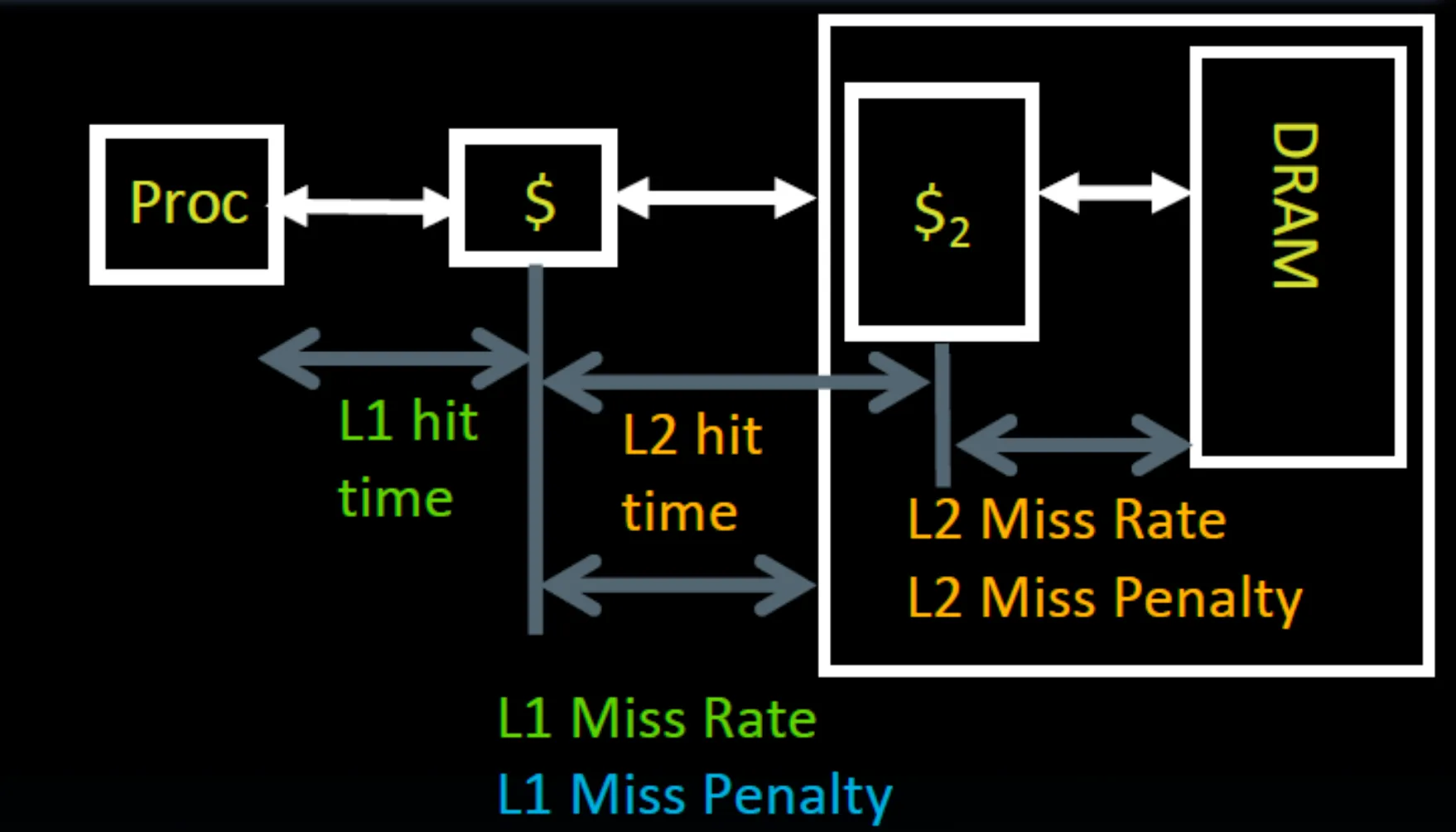
上图是对访问延迟的分解表示,真正访问 Memory 的概率为 L1 Miss Rate * L2 Miss Rate。
衡量性能时,还是需要计算 CPI:
循环分块#
不是减少计算量,而是减少 Cache miss,提高数据局部性。
从最经典的例子开始,一个 C 语言下的矩阵乘法。
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
for (k = 0; k < N; k++)
C[i][j] += A[i][k] * B[k][j];由于 C 语言中数据是按行连续存储的, 连续访问的元素在内存中不连续,产生大量 cache miss,数据反复从内存加载。
我们需要 把“大循环”拆成“能装进 Cache 的小块”,让数据在 Cache 里被反复用完再换掉。
Virtual Memory#
Virtual Memory Basics#
Virtual Memory:
- Memory + Disk + OS
- 是一种机制,它让主存(DRAM)充当了磁盘(Disk)的缓存。
- 把 Disk 提供给 CPU 一个虚拟的 Memory 地址空间,让 CPU 可以像访问 Memory 一样访问 Disk.
- 每个程序拥有私有的虚拟地址空间,虚拟空间一定要映射到物理空间。
- Disk 和 Memory 之间以 Page 为单位,交换数据。
Memory Layout
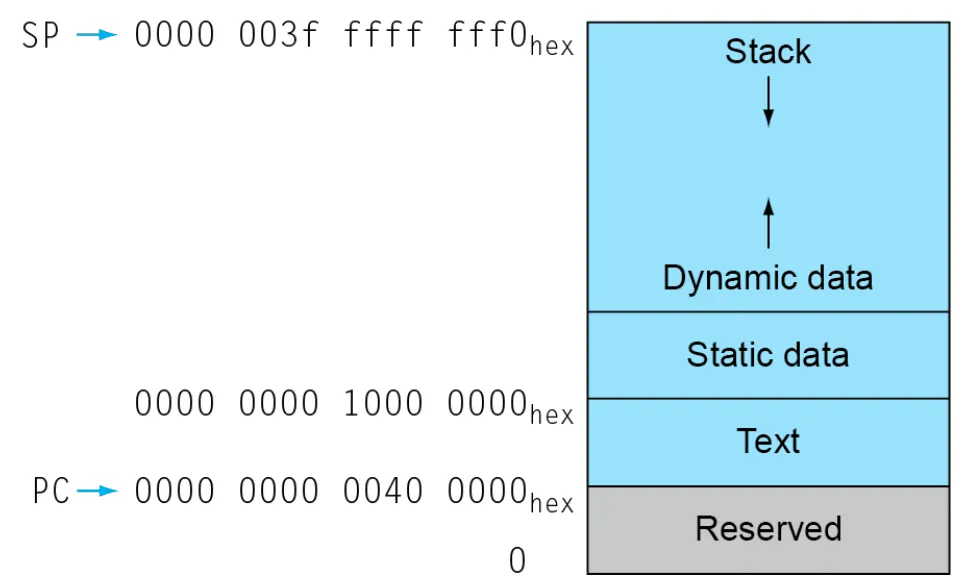
下面讲解如何实现上述功能。
Address Translation 地址转换#
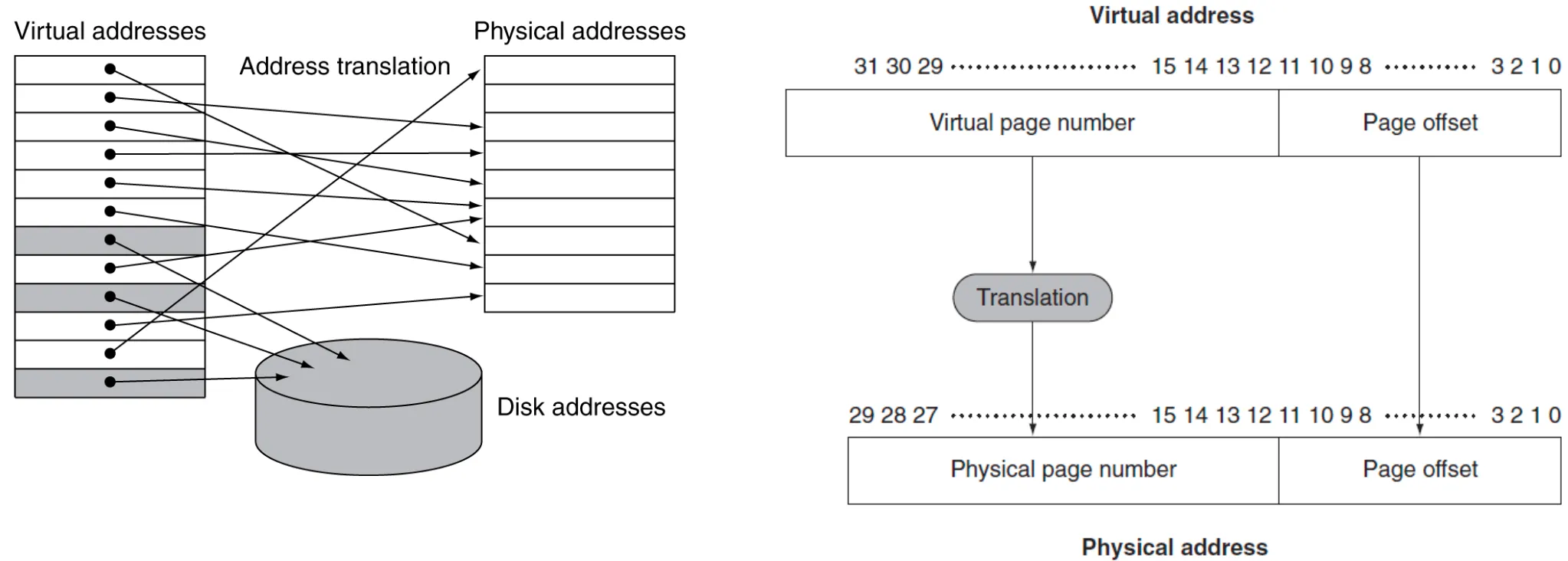
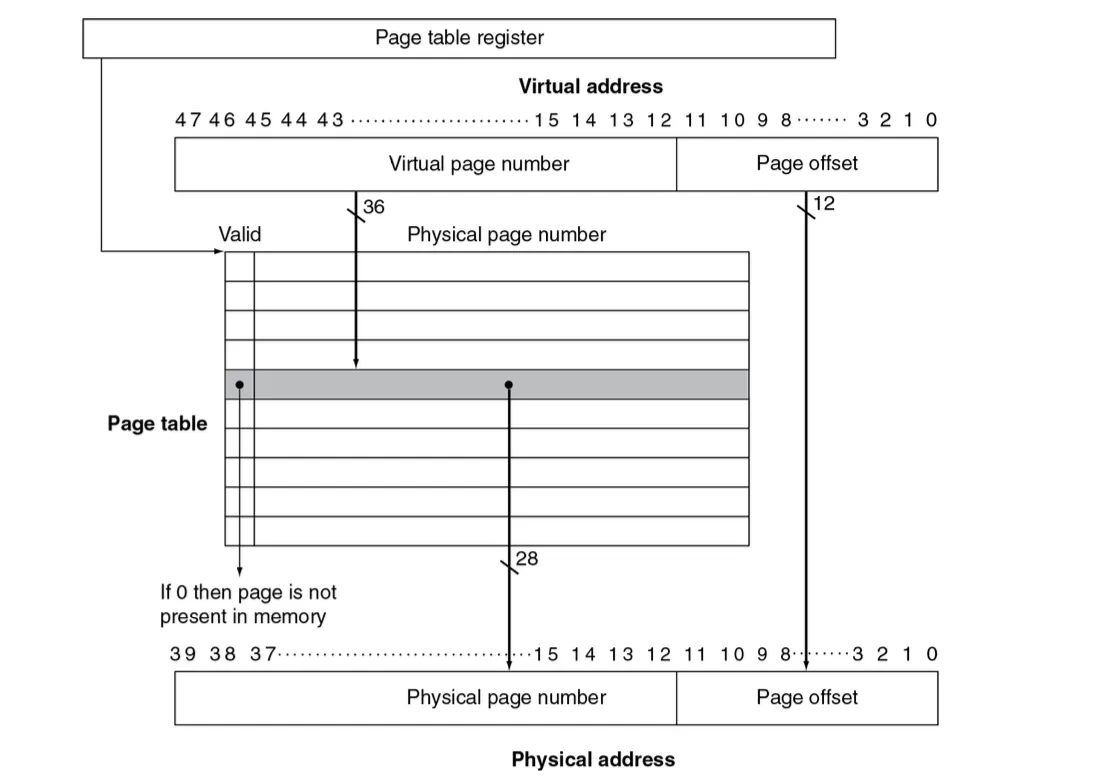
左图是虚拟存储和物理存储的关系,以页为存储的基本单位(一个页是一个固定的大小)。其中有两种地址:
- 虚拟地址 Virtual Address
- 物理地址 Physical Address
地址较低位是 Page Offset 页内地址;较高位是 Page Number 页号,因此:
- VA 的结构为:| VPN | Offset |
- PA 的结构为:| PPN | Offset |
我们要把 Virtual Address 对应到 Physical Address,只需要 Virtual Page Number 转换为 Physical Page Number,页内偏移量 Offset 保持不变,这就是 Address Translation 过程。
Page Table 页表#
上面的 Translation 过程需要维护一个 页表 Page Table。
下图是页表的作用。
基本结构#
每个页表项 Page Table Entry 对应一个虚拟页号VPN,在表中可以查询到 虚拟页号 VPN 对应的:
- 物理页号 PPN:物理内存中的位置
- 有效位 Valid Bit:
- 1 表示,在主存 Memory 中,正常;
- 0 表示,不在主存 Memory 中,此时 PTE 里存的通常是 Disk Address。
- 为 0 时,必定触发 Page Fault,进入 OS 中对应的异常处理程序,处理后,会把 Disk 内容读取到 Memory 中,之后PTE 存的就是 Memory Address了,详见后文。
页表存储在哪?多进程?
每个进程都有一个自己的页表。
正在运行的进程,其页表存储在 CPU 中的页表寄存器。
CPU 中有一组特殊寄存器,只有内核态(正在运行的进程)可以访问,称为 控制状态寄存器 CSR。
下图是页表的运行过程。
大页表优化#
如果虚拟地址空间很大,页表本身就会变得巨大无比,难以全部塞进内存。有几种处理方案:
- 界限寄存器 Limit Register:
- 使用一个寄存器来限制页表的大小,只为进程实际使用的部分分配页表。
- 因为大多数进程实际上只使用了虚拟地址空间的一小部分,页表只需要覆盖进程实际使用的地址范围。
- 反向页表 Inverted Page Table:
- 按物理页号索引,而不是虚拟页号,只需要一张表;
- 大幅减小表的大小,但没法快速查找,遍历比较慢。
- 多级页表 Multiple levels of page tables:
- 将页表分层,类似于目录的目录。一级页表的每项,指向一个二级页表,以此类推。
- 优点在于可以按需分配:只有一级页表常驻内存,其他页表按需创建。如果某个大范围的虚拟地址没有被使用,整个二/三级页表都不需要创建。
- 极大地减少了内存占用,也不需要连续的大块内存,是目前最主流的实现方式。
Page Fault#
当 Memory 中没有,只在 Disk 中有数据的时候,OS 需要花费大量时间,把缺失的页从 Disk 调往 Memory。然后更新页表的 PPN 为 Memory 中的一个物理地址,更新 Valid Bit 为 0.
因此需要尽可能减小 Page Fault Rate.
Replacement and Writes#
这部分和 Cache 很类似。
Replacement:
- Memory 满了的时候需要替换一些来自 Disk 的页。
- 可以采用 LRU 算法,和 Cache 中的实现基本一样。在上述 Page Table 的基础上,加一个 Reference Bit,表示 页面最近是否被访问过。被访问时,该位置1,操作系统定期清零。替换时选择一个为 0 的页来替换。
Writes:
- 写 Disk 非常慢,且必须按页写入,不能只写一个字节。因此 Write-through 的效率是不能接受的。
- 只能采用 Write-back 策略。只更新 Memory 中的 Page,只有当 Page 被替换时,才将其写回 Disk.
- 硬件上,和 Cache 一样,需要在 PTE 中加一个 Dirty bit,标记该内容是否需要写回磁盘。
Translation Look-aside Buffer, TLB#
定义#
TLB 简称 快表,是 CPU 内部的一个专用高速缓存,专门用来存储最近使用的页表项。
只在 CPU 中有一个,因此 TLB 只存储正在运行的进程,切换进程时清空。
TLB 的命中率非常高,99%以上。
TLB 可以理解为页表的 Cache,页表的部分内容映射到 TLB。
结构#
和 Cache 非常类似。
内部组成:TLB 的每一行通常包含以下部分:
- Tag:虚拟页号 (Virtual Page Number) 的一部分。
- Data:物理页号 (Physical Page Address)。
- 状态位:Valid, Dirty, Ref.
由于 TLB 很小,为了降低缺失率,通常采用全相联结构。
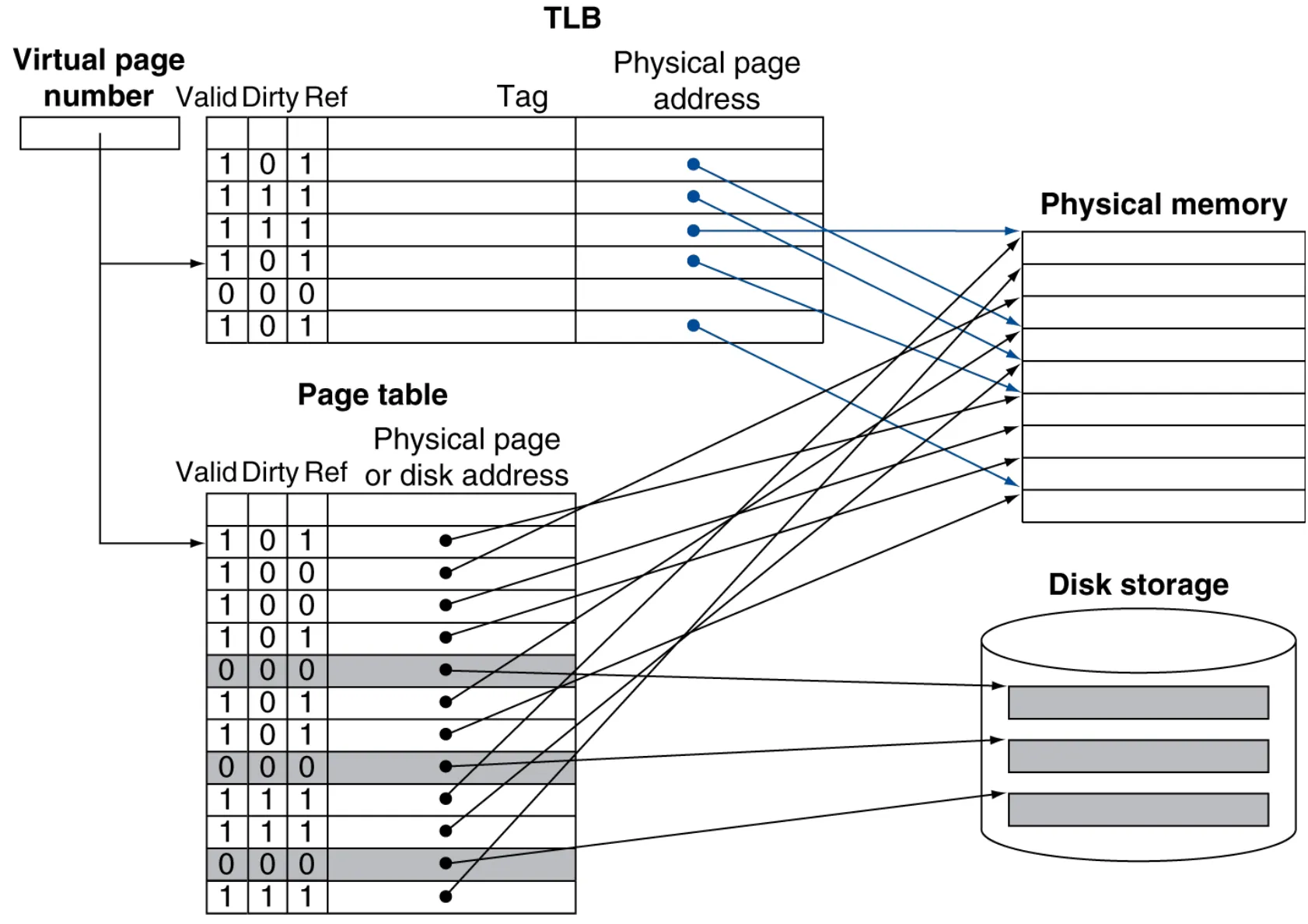
TLB Misses#
有两种情况:
- A:页面在主存中,只是 TLB 没记录。
- 从内存中的页表加载 PTE 到 TLB,然后重试。
- B:Page Fault,页面不在主存中
- 触发缺页异常,由操作系统 (OS) 处理,从磁盘读取页面。
- 不归 TLB 处理。
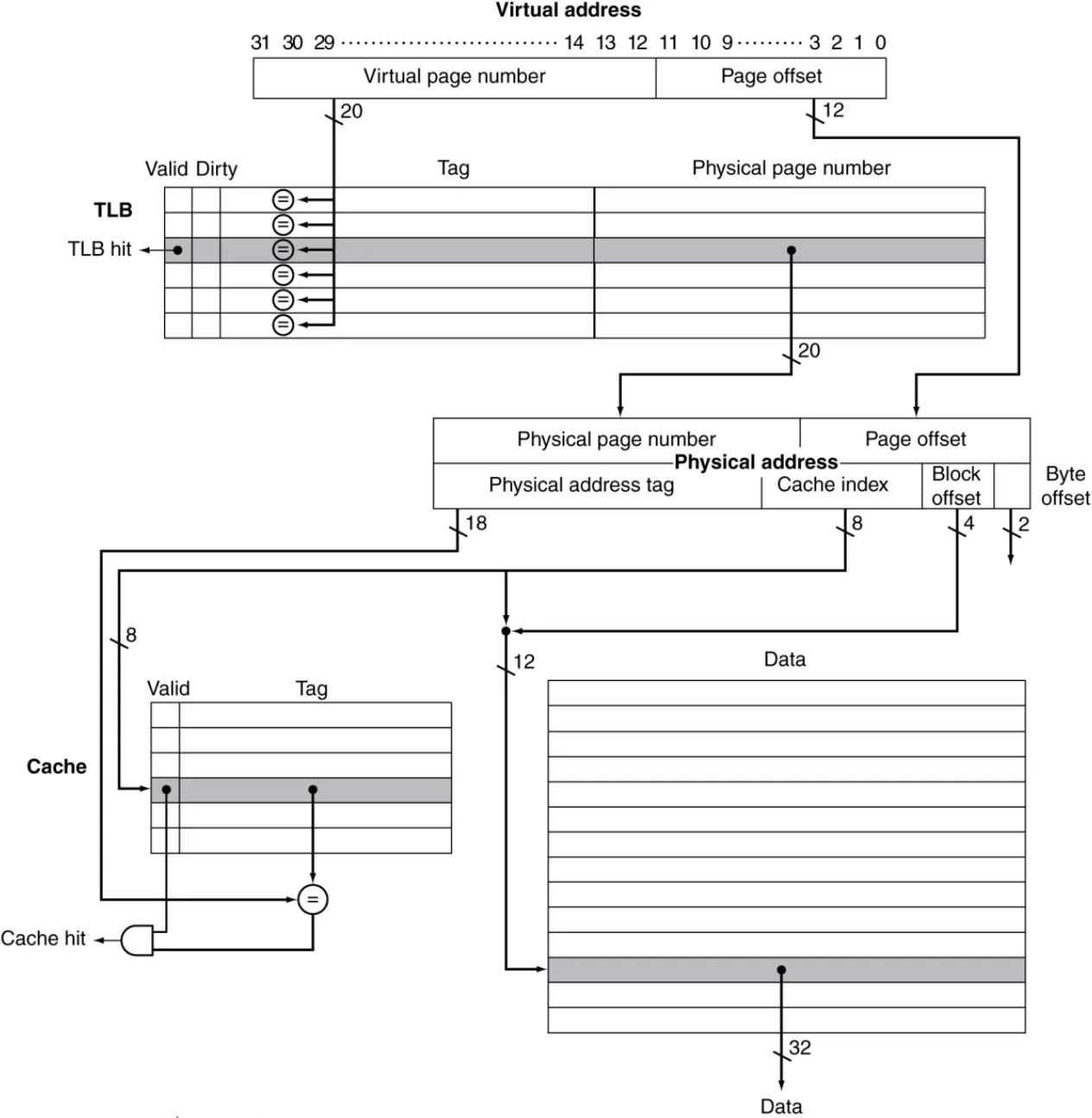
Interaction with Cache#
访问流程:
- CPU 发出虚拟地址,给 TLB。
- TLB 将虚拟地址转换为物理地址,若缺失就访问页表。
- 使用物理地址访问 Cache。
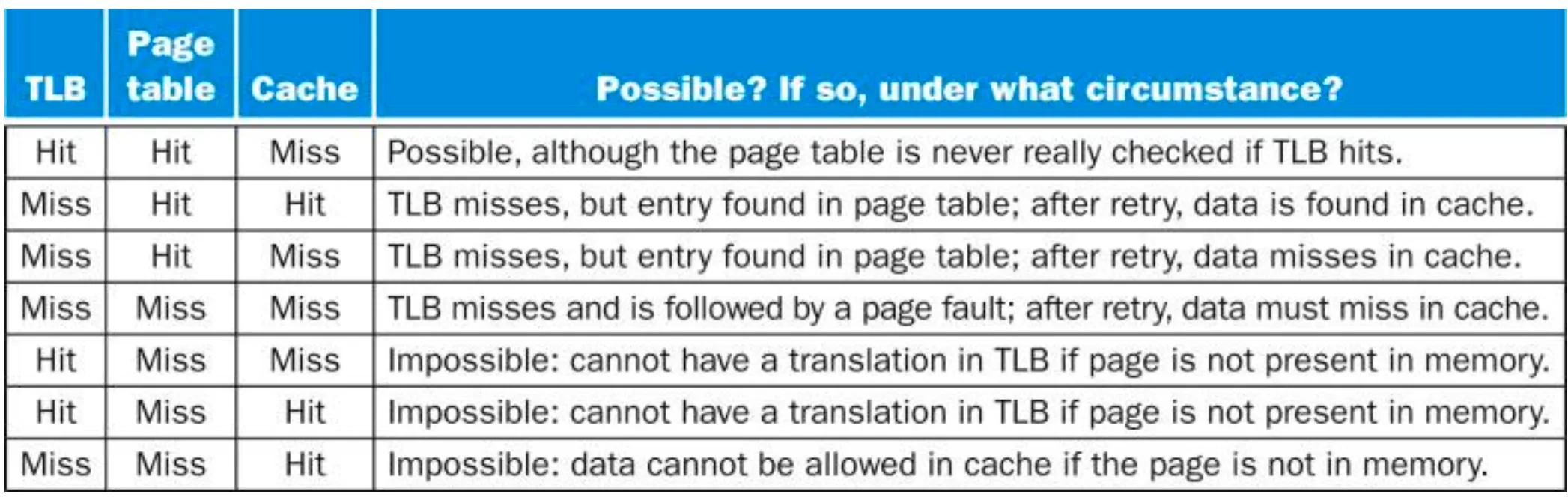
命中情况真值表:只有前四种是可能发生的。
Memory Protection#
多个进程可以共享内存,但必须防止它们乱访问彼此的数据。
用户态 / 内核态权限管理。
Dependability#
内存可能出错,需要很好的校验、纠错机制。
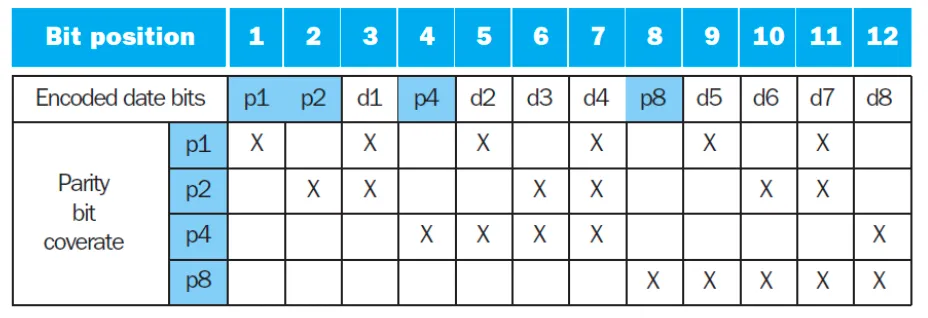
下面是 1bit 的校验和纠错算法。
规则
- 编号:位编号从 开始。
- 校验位:选取 为校验位。
- 校验位 的范围:编号的二进制表示中,第 位为 的所有 bit。
Encoding
- 偶校验:给校验位 或者 ,使校验位覆盖的所有 bit 中,有偶数个 1。
Decoding
- 找错误:根据目前值,重新计算所有校验位。若 ,说明该校验位错误。
- 纠错:假设 ,可知编号第 位为 的 bit 出错,也就是第 5 位出错,对应 。纠错只需要将其取反即可。
如果需要 2bits 的校验,注意到,上述算法可能不起效,因为两个错就可以让偶校验失效。
2bits 校验
- 引入全局校验位 ,对 整个码字 做偶校验。
- 若前面的校验位对 1bits 校验提示有错误,但 没错,则说明是 2bits 错误。
- 同样兼容 1bits 错误纠错:当 显示错误,1bits 也显示错误,则是此类情况。
- 并不能具体判断出是哪 2bits,不具备 2bits 纠错功能。
The BIG Picture#
Cache、虚拟内存等其实都遵循同一套思想,都有四个核心层级:
- Block placement:数据怎么存?
- Direct mapped
- n-way set associative
- Fully associative
-
Finding a block:数据怎么检索?#
- Replacement:存满了,换谁?
- LRU
- Random
- Write policy:怎么写数据?
- Write-Through 写直达
- Write-Back 写回
- VM 只能接受 Write-Back,因为磁盘写入太慢了。